核心技术
场景定义算法,算法定义芯片,通过自定义指令集、处理器架构及工具链的协同设计,实现算法芯片化
图灵微秉承"以应用场景为导向"的技术理念,深度理解各类AI应用场景的算法特点和计算需求, 从底层指令集设计到上层工具链优化,形成完整的AI芯片技术栈,为客户提供高性能、低功耗的AI计算解决方案。
芯片架构发展历程
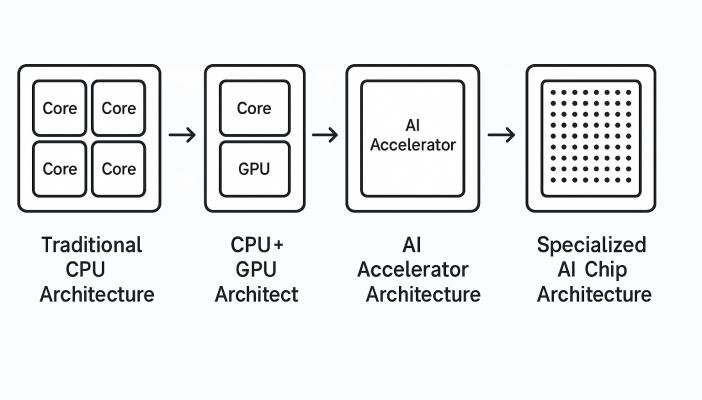
从传统CPU架构到专用AI芯片架构的演进路径
三大技术支柱
自主指令集
灵活可扩展的神经网络处理器指令集,支持训练与推理一体化处理。基于RISC-V架构扩展,针对深度学习算法特点进行定制优化,实现高效的矩阵运算、卷积运算和激活函数处理。支持动态图和静态图两种计算模式,为不同应用场景提供最优的计算效率。
软件定义架构
动态可重构的存储融合架构,实现低功耗与高性能的完美平衡。采用近存储计算技术,大幅降低数据搬移功耗;支持稀疏化计算,有效提升计算效率;具备灵活的可重构能力,可根据不同算法需求动态调整计算资源配置,最大化硬件利用率。
自适应工具链
一键式模型部署平台,加速算法到芯片的迭代周期。集成模型优化、量化压缩、编译优化等全流程工具,支持主流深度学习框架(TensorFlow、PyTorch、Caffe等);提供可视化调试环境和性能分析工具,帮助开发者快速定位和解决性能瓶颈。
技术优势
高性能计算
通过定制化指令集和优化的处理器架构,实现比通用处理器高10倍以上的AI计算性能
超低功耗设计
采用近存储计算和稀疏化技术,功耗比传统方案降低80%以上,适合边缘计算应用
灵活可扩展
支持多种AI算法和应用场景,可根据客户需求进行定制化设计和优化
快速部署
完整的工具链支持,从算法到芯片的部署时间缩短至传统方案的1/10
生态兼容
支持主流深度学习框架,兼容现有软件生态,降低客户迁移成本
全栈服务
从芯片设计到系统集成,提供完整的技术支持和解决方案服务